Our Real-time Personalization Platform
Scalable, robust Java application developed from scratch for the purpose to provide access to the source code of the machine learning algorithms and the application itself.
H
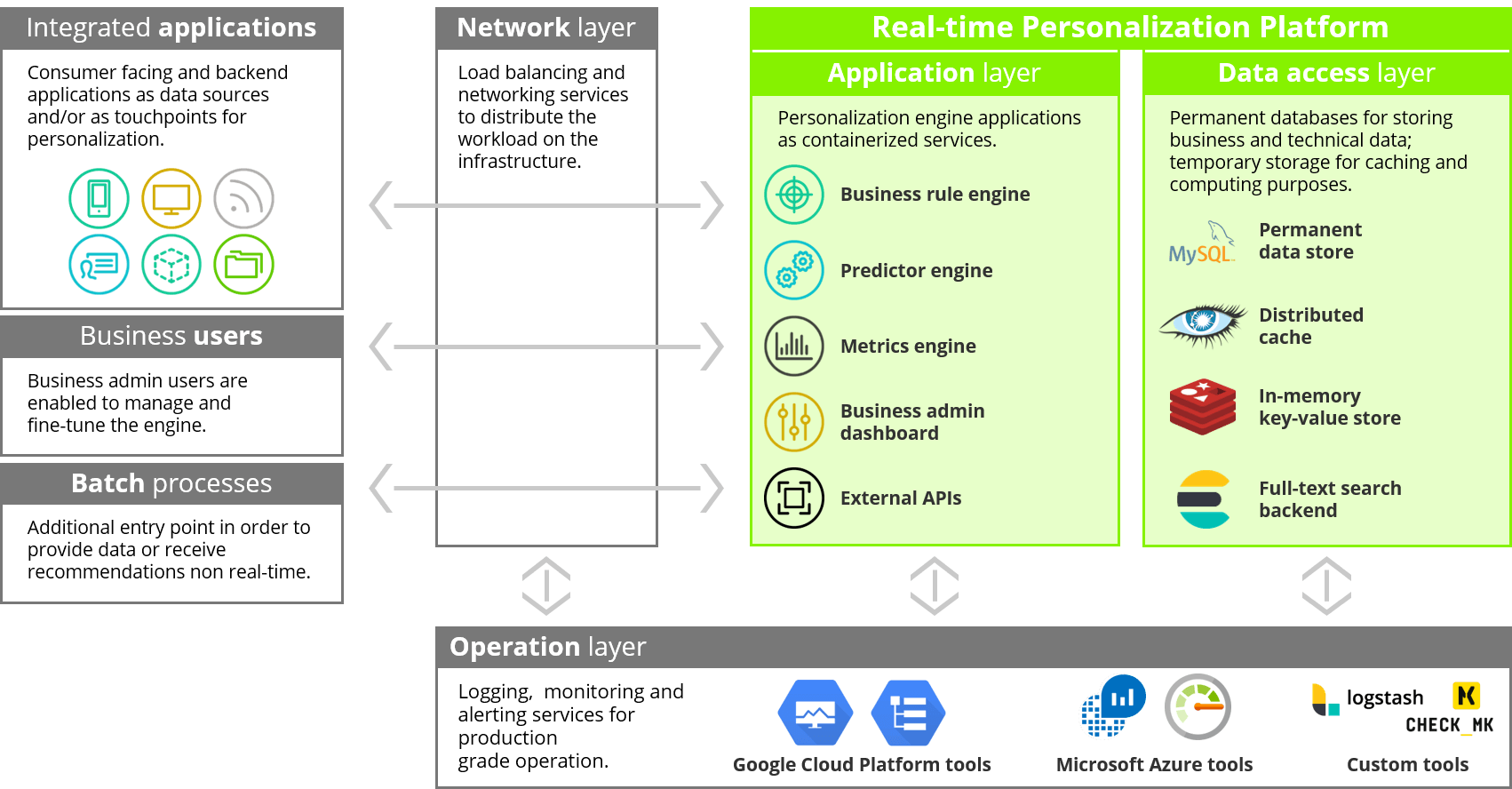
High-level Architecture
From software architecture point of view, the capabilities are provided by two major components: (1) backend and (2) frontend. Most of the features are provided by the backend part, more precisely all the features and services could be fulfilled by the backend part in theory. The aim of the frontend part is to provide an easy-to-use UI to (a) setup, configure and fine-tune recommendation logics without having deep developer and/or mathematician knowledge; (b) without having direct access to the backend engine. The integration between the backend and the frontend needs to be done by specific API calls.
Backend
Backend, or in other terms the engine itself is a standalone and stateless application. It can be accessed from the outer world through RESTful APIs. From high-level software architecture point of view, it contains the following modules:
- Core modules
- Predictors: implementation of the recommendation algorithms.
- Rule engine: provide the framework for configuration of recommendations logics (proper selection, configuration and blending of the different algorithms and business rules).
- Metrics: responsible to aggregate and store measurements.
- API listeners
- External APIs: access point towards the outer world.
- Internal APIs: internal APIs for the frontend, for health check and administrative purposes
- Utilities
- Configuration: provides all necessary configuration for modules.
- Logging: provides logging capabilities.
- Command Line Interface: management commands and running batch processes (import and batch recommendation).
Frontend
Frontend part of the solution is an easy-to-use user interface. Its main goal is to enable end users – mainly business people – to setup, configure recommendation logics, and send it to the engine. On the top of that, frontend is also capable to display metrics/analytics from the engine in a visual way.
Data stores
Engine backend is connected to persistent data stores, as well as to temporary data stores for caching and distributed computing purposes.
Integration
From high-level integration point of view, the personalization engine receives and stores data from source systems/streams/databases and provides recommendations to target systems/streams/databases. Our personalization engine has its own out-of-the-box APIs in order to receive input and provide output, however the source and/or target systems should not be expected to have the same interface signature. In this case additional integration layer need to be used.
Metrics
Evaluation of the results and the efficiency of personalization, as a type of (big) data initiative, should be based on KPIs. The proper metrics framework, including the clean and commonly aligned definitions, measurement units need to be defined prior to the technical implementation. KPIs should represent business priorities of the clients, therefore different metrics should be used for different industries / domains.
KPIs can be also dependent on the actual project circumstances. Different metrics setup is required to compare two (or more) personalization engines in an A/B test and to measure revenue increase or click-through-rate.
KPIs need to be measurable continuously in order to see both the trends of the performance on the top of the actual results. Detailed evaluation report is proposed to be created time by time, e.g. after fine-tuning periods, after new placements and/or modules implemented.
H
Core Capabilities
Real-time personalization requires three steps:
- Real-time data gathering – gather data about a visitor or group of visitors. This data can come from a variety of sources, including on-site session data, explicit profile data, historical transaction or browsing data, geolocation data and external data, such as open APIs.
- Analysis – run data through proprietary machine learning algorithms to suggest personalization techniques or strategies. This can happen in real time or through batch processes.
- Presentation layer changes – act on the analysis and change the presentation layer content to the customer.
Although all personalization engines gather and analyze data, not all personalization engines make the presentation layer change for the customer, which makes this one of the distinguishing factors among personalization engines. If the personalization engine does not make changes to the digital presentation layer for the customer, the suggestions of the personalization are fed to another application, such as web content management or another service, such as email service providers. These, in turn, make the presentation layer changes.
Capability classification below follows the terminology of Gartner.
In-session behavior tracking, data collection and ingestion
Our Javascript framework can be used on a website (or any other web-based touchpoint) to directly connect it to the engine backend in order to capture and store the events on the particular touchpoint.
Ingestion of user action e.g browsing, view, buy, share, like rate, including action details, e.g. view percentage, rating score. It can be: (i) a user only event (e.g. user logged in into the site), (ii) events connected to items (transaction events).
Ingestion of events non related to specific users (e.g. item price change, item availability change).
Ingestion of user profile data, or anything related (e.g. external segmentation information).
Ingestion of properties of items that will be available for recommendation (in specific cases also the item availability for recommendation).
Data ingestion real-time, or almost real-time. Scenarios will be able to use this data (user/events/items) right after ingestion.
Data ingestion that is happening periodically (e.g. hourly, daily, on-demand). Personalization engine will only use this new data after the scheduled ingestion.
The system does match different type of user identifications into one single user (e.g. user is not always logged into the system while browsing, or connecting the user on different devices – userId, deviceId, mobile app id).
The system does not let event ingestion duplication occur with different sources (e.g. in case of hybrid live and batch ingestion not letting the same event imported twice).
Format of the specific API calls are different than the ones exposed by the system.
Data manipulation happens before the data import, so the system is not directly responsible for transforming data, only in very simple cases (e.g. renaming data fields, removing fields).
Exposing back the loaded user profile data.
Exposing back the loaded item data.
The system uses commonly used persistent data stores.
The system uses commonly used temporary data stores and distributed computing resources.
Predictive analytics, data modeling and user segmentation
Rule-based segmentation can be done through the frontend, where there is possibility to define and reuse segments, moreover to be able to perform queries on that segments (e.g. which users belongs in which segment).
Methodology-based segmentation is performed in external tools (e.g. with Python scripts), and the personalization engine processes it as inputs with integration.
A/B and multivariate testing, and algorithmic optimization
Through the frontend there is the possibility to setup easily and conduct basic, such as A/B and A/B/C/D testing, and optimization.
Acceptance testing protocols and acceptance test for the generic solution are available.
Functional testing on different abstraction layer and component integration are covered with proper test tools. The smallest possible elements of the program are covered with tests.
Rule- and algorithm-based targeting across touchpoints
Setup and configure recommendation logics for personalized content, offers, messaging and/or experiences, to both anonymous and known users, via web, email marketing, mobile app engagement, mobile messaging, digital advertising and retargeting.
Setup and configure recommendation logics for personalized content, offers, messaging and/or experiences, to both anonymous and known users via HTML and JavaScript on elements of digital commerce sites, mobile commerce sites, mobile commerce applications and point of sale including, but not limited to, homepage(s), category landing page(s), product detail page(s), on-site search and navigation, and product recommendations.
Setup and configure recommendation logics for personalized experiences beyond sales and marketing, online and offline, to both anonymous and known users, across touchpoints, including, but not limited to, chatbots, voice assistants, digital kiosks, interactive voice response (IVR), clienteling applications and call centers.
Recommendation logics can be tested in staging mode prior to put apply changes on the production environment.
The recommendations can be requested both by requests and in push mode through API calls.
Next best action or offer, and product and content recommendations
The personalization engine suggests a highly relevant product or content as a NBO, in terms of pricing a combination of profit and affordability will be estimated. In comparison to personalization engine only, we do not provide just ranking but also conversion probabilities. In comparison to just an offline probability to buy or probability to subscribe estimation, our models are updated in real-time, therefore they do not get obsolete. The previous campaign setups in the personalization engine can be reused for the next campaigns, as only the target needs be redefined. Probability of churn can be estimated as well by using the same personalization engine.
Next best recommendation probabilities can be estimated for several other attributes, as follows: sending time of the messages, Email subject line, different design elements, for example, background color, variants of the same text, for example, discount in % or absolute number, next best action, etc.
The personalization engine can be deployed as a lightweight solution if real-time capabilities are not needed.
Setting up editorial recommendation.
Filter out items based on rules (e.g. fixed items, type of items, complex rules).
Ability to score the items based on how similar an item is to another recommendable item (ItemToItem Predictor).
Scoring the item based on how relevant the item is to a user (ItemToUser Predictor).
Conditional based pushing of specific items (e.g. giving higher relevance in personalization for specific type of items).
Sorting of items.
Giving paging capability on the recommendation result set.
Grouping items by specific condition, and limiting the number of items in each group.
Creating complex data flows by using the combinations of the above logics.
The ability to use externally calculated algorithm models (a.k.a. externally trained models) in the personalization engine through standardized interfaces, to give the ability to use algorithms developed by the client, or 3rd party algorithms.
Personalization performance tracking, measurement and reporting
The system has the capability to setup, track and store KPIs and health checkpoints for different stakeholders (e.g. operation KPIs for OPS, business KPIs for business stakeholders).
Easy-to-use KPI setup interface; native integration with the personalization engine; basic visualization capabilities (charts, bars).